본 게시글은 멋쟁이 사자처럼 AI스쿨 7기 수업에서 배운 내용을 바탕으로 작성하였습니다.
지금까지 추상화된 도구로 기술통계를 구하는 방법과
수치형 데이터의 기술통계를 직접 구하는 방법을 배웠다.
이번에는 범주형 데이터의 기술통계를 직접 구하는 방법에 대해 배워보도록 하자.
(사용 라이브러리: pandas, numpy, seaborn, matplotlib)
[Python] 기술통계1 - pandas profiling, sweetviz, autoviz
https://jeongsooyoon.tistory.com/entry/Python-%EA%B8%B0%EC%88%A0%ED%86%B5%EA%B3%84?category=1070760
[Python] 기술통계2 - 직접구하기(수치형 데이터)
데이터셋을 불러오고 데이터셋에 대한 기본 정보(info, head, tail, 결측치 등)를 확인하는 방법이 기억안난다면,
이전 글에서 다시 공부하고 오자.
또한, 범주형 데이터에 대한 기술통계를 불러올 경우 개수, 고유값, 최빈값(top), 최빈값의 빈도수(freq)임을 기억하자.
(※ 수치형 데이터의 기술통계: 개수, 평균, 최소, 최대, 4분위수 ...)
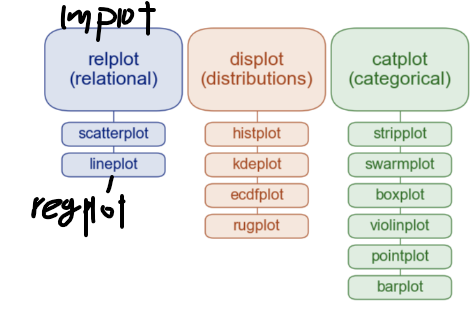
보통, relplot과 displot은 수치형 데이터를 표현할 때 사용하고 catplot은 범주형 데이터를 표현할 때 사용한다.
다만, 지난 번에 수치형 데이터의 기술통계 그래프에 대해 학습할 때 boxplot, violinplot 등을 그려봤다. 해당 plot들은 수치형과 범주형 데이터 모두에 사용할 수 있는 plot이다.
1. 범주형 데이터의 빈도수
- 데이터명["변수명"].nuique( ): 지정한 변수의 고유값의 빈도수를 출력한다.
- 데이터명["변수명"].unique( ): 지정한 변수의 고유값을 나열해준다.
※ unique는 시리즈만 가능하고, nunique는 시리즈와 데이터프레임 둘 다 사용할 수 있다.
가. Countplot (1개 범주형 변수에 대한 빈도수 그리기)
- 데이터명["범주형 변수"].value_counts( ): 변수의 빈도수 출력
- sns.countplot(data = 데이터명, x = "x축 변수") : x축 변수를 기준으로 구분하여 빈도수를 나타낸 그래프이다.

- sns.countplot(data = 데이터명, y = "y축 변수") : 축을 y축으로 변경해서 그릴 수 있다.
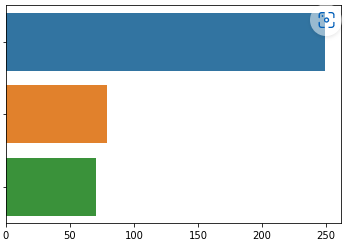
나. Countplot (2개 이상의 범주형 변수에 대한 빈도수 그리기)
countplot으로 2개 이상의 변수에 대한 빈도수 그래프도 그릴 수 있다.
- sns.countplot(data = "데이터명", x = "x축 변수", hue = "hue 변수")
: x 축에 하나, hue로 하나 지정해서 2개의 변수에 대한 plot 출력 (지정하지 않은 축, 여기서는 y 축은 count를 가져간다.)
- countplot에서는 x축과 y축 모두 지정하게 되면 오류가 나니까 주의하자.


위와 오른쪽 그래프 중에 어떤 것이 더 보기 편한가?
취향차이 이기는 하지만, 일반적으로 오른쪽 그래프가 더 한 눈에 보기 쉽다. 색깔 (즉 hue 값 = 범례값)은 3가지가 넘지 않도록 설정하는 것이 좋다.
다. pandas의 crosstab으로 빈도수도 구할 수 있다.
- pd.crosstab(index = df["변수명 = hue 값"], columns = df["변수명 = x축 변수"])
2. Barplot (기본값: 평균)
barplot의 기본 estimator는 평균이다.
- sns.barplot(data = 데이터명, x = "범주형 변수", y = "수치형 변수", ci = None)
여기서는 x축에 범주형 변수, y축에 수치형 변수를 지정해줬다.
그럼 범주형 변수를 기준으로 나누어서 수치형 변수에 대한 평균 값을 그래프로 나타내게 될 것이다.

평균이 아닌 다른 값을 출력하고 싶다면 어떻게 해야할까? estimator에 구하고자 하는 바를 지정해주면 된다.
- sns.barplot(data= 데이터명, x="범주형 변수", y="수치형변수", estimator=np.sum, ci=None)
: 수치형 변수에 대한 sum을 출력한다.

- sns.barplot(data = 데이터명, x="범주형 변수1", y="수치형 변수1", hue="범주형 변수2", ci=None)

3. 연산(groupby, pivot_table)
가. groupby를 통한 연산
- 데이터명.groupby("범주형 변수명")["수치형 변수명"].mean()
- 데이터명.groupby(["범주형 변수명"])[["수치형변수명"]].mean()
위 두개의 코드 모두 범주형 변수명을 기준으로 그룹화하고 수치형 변수에 대한 평균을 출력할 것이다.
다만 차이가 있다면 첫 번째는 [ ] 를 사용했고, 두 번째는 [[ ]]를 사용했다.
첫 번째는 일반 줄글(?)형태로 출력할 것이고, 두 번째는 데이터 프레임 형태로 출력할 것이다.
( [ ]: 시리즈, [[ ]]: 데이터프레임)

그리고 groupby에 2개의 기준을 입력할 수도 있다.
- 데이터명.groupby(by=["범주형 변수1", "범주형 변수2"])["수치형 변수"].mean()
언스택은 마지막 인덱스를 위로 가지고 오는 역할을 한다.
- 데이터명.groupby(by=["범주형변수1", "범주형변수2"])["수치형 변수"].mean().unstack()

다. pivot table을 통한 연산

- pd.pivot_table(data=데이터명, index="범주형 변수", values="수치형 변수")
데이터를 범주형 변수로 인덱스를 구분하고, 수치형 변수에 대한 값을 데이터프레임으로 출력한다.
여기서도 기본값은 평균이다. 즉, 평균 값을 데이터 프레임 형태로 출력해주는 것이다.
이렇게 하면, 두 개의 범주형 변수로 나누고 수치형 변수의 평균 값을 데이터 프레임 형태로 출력을 하게 된다.
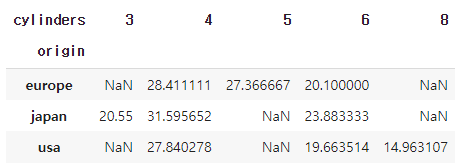
pivot과 pivot_table
pivot과 pivot_table의 가장 큰 차이는 연산 여부이다.
4. Boxplot(상자수염그림)
boxplot은 지난 번에 수치형 데이터의 기술통계 시각화에서도 배워보았다.
이번에는 범주형 데이터의 기술통계를 boxplot으로 그려보자.
- sns.boxplot(data = 데이터명, x="범주형 변수", y="수치형 변수")

가. 특정 변수에 대해서만 boxplot 그리기
- sns.boxplot(data = 데이터명[데이터명["범주형 컬럼명"] == "범주형 변수"], x="수치형 변수")
불리형 인덱싱으로 해당 조건에 부합하는 변수에 대한 boxplot만 그려봤다.

나. 특정 변수에 대해서만 Boxenplot
- sns.boxenplot(data = 데이터명[데이터명["범주형 컬럼명"] == "범주형 변수"], x="수치형 변수")

(참고) 다. 특정 변수에 대해서만 violinplot 그리기
- sns.boxplot(data = 데이터명[데이터명["범주형 컬럼명"] == "범주형 변수"], x="수치형 변수")

5. 범주형 변수의 산점도 그래프 그리기
가. scatterplot
- sns.scatterplot(data = 데이터명, x="범주형 변수", y="수치형 변수")
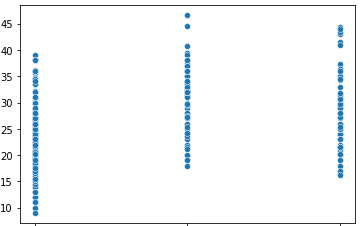
나. sripplot
- sns.stripplot(data = 데이터명, x="범주형 변수", y="수치형 변수")

라. catplot
- sns.catplot(data = 데이터명, x="범주형 변수", y="수치형 변수")

catplot을 활용하여 범주형 데이터의 서브플롯을 표현할 수도 있다.
sns.catplot(data = 데이터명, x = "범주형 변수", y = "수치형 변수", kind = "box", col = "subplot(범주형 변수2)")

sns.catplot(data = 데이터명, x = "범주형 변수", y = "수치형 변수", kind = "violin", col = "subplot(범주형 변수2)")

sns.catplot(data = 데이터명, x = "범주형 변수", kind = "count", col = "subplot(범주형 변수2)", col_wrap = 3)

col_wrap 은 한 줄에 몇 개의 그래프를 나타낼 것인지 지정하는 것이다.
(위에서도 언급했지만, countplot은 x와 y축 모두 지정하면 오류가 나게 된다.)
'Python > EDA' 카테고리의 다른 글
| [Python] 기술통계2 - 직접구하기(수치형 데이터) (0) | 2022.09.29 |
|---|---|
| [Python] 기술통계1 - pandas profiling, sweetviz, autoviz (0) | 2022.09.29 |